Overview: ESG workflow
Get a quick overview of our ESG workflow to learn more about how we use AI to provide ESG controversy data.
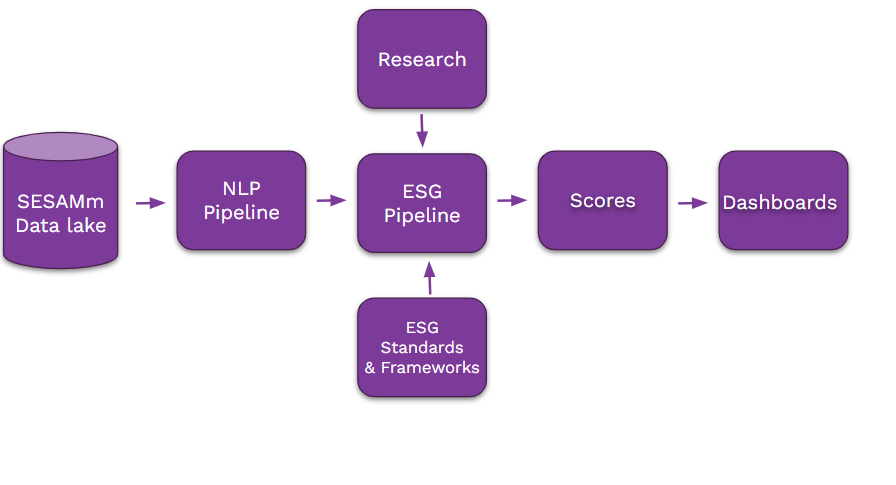
SESAMm’s ESG event detection process begins with a powerful Natural Language Processing (NLP) pipeline, which prepares and analyzes incoming documents at scale. This pipeline extracts key features such as sentiment, named entities (e.g., company names), and other structured data using a combination of large language models (LLMs) and deep learning techniques.
Once enriched with this core information, these documents are handed off to the specialized ESG Pipeline. This second stage focuses on identifying and organizing ESG-related content, ensuring relevance, accuracy, and context. The ESG Pipeline refines the information to surface daily updates on controversies, assign risk categories, and calculate exposure scores for monitored entities. The entire process is automated and runs daily.

Key Steps in the ESG Pipeline:
1. Document Filtering & Clustering
The process starts by filtering extracted documents for relevance. Using an advanced Natural Language Processing algorithm, documents are then grouped by topic into daily clusters. Only the main document from each cluster continues through the pipeline.
2. Document Insights
Each document is analyzed by a state-of-the-art LLM that contextualizes the impact on the company and assigns an intensity score estimating the severity or impact of the ESG issue. Additionally, key insights are extracted to summarize the most relevant information from the text.
3. Annotation
The documents are annotated to confirm two things:
- The content describes an ESG-relevant event
- The event involves an entity monitored in SESAMm’s Event Monitoring universe.
Once again, an LLM is leveraged. It conducts automated checks, systematically reviewing documents to ensure the content is both relevant and accurate. By focusing on ESG or SDG compliance and targeted company mentions, this step ensures that you are presented with only relevant content.
4. Event & Case Clustering
Once again, we leverage an advanced NLP algorithm to group documents into coherent events, which are then aggregated into larger cases to track the evolution of each controversy. Visit here for more information on Event & Case Clustering.
5. Event & Case Enrichment
Using LLMs, each event and case is enriched with titles, summaries, ESG risk category, ESG sub-risk, and intensity score.
6. ESG Categorization
Next, an NLP algorithm-based refinement step is applied to reassess and, if needed, update the ESG risk and sub-risk classifications assigned during earlier stages. This step ensures greater accuracy and alignment with SESAMm’s ESG taxonomy.
7. Controversy Exposure Score
Finally, SESAMm calculates a daily ESG Controversy Exposure Score (CES) for each monitored entity. This score reflects the entity’s recent exposure to ESG-related risks based on the volume and severity of associated events. Learn more about the CES here.
Output
At the end of the ESG pipeline, clients receive structured and enriched data ready for analysis and decision-making, including:
- Filtered and relevant documents
- Detected ESG events with intensity score
- Structured cases tracking those events over time
- Daily CES scores for each monitored entity
These outputs power ESG monitoring, due diligence, and risk assessment workflows with timely and traceable insights.